别只顾着追赶 OpenAI,成为估值 1830 亿美元的 Anthropic 也不错
上周,OpenAI 和 Anthropic 分别发布了一份人们如何使用其 AI 的报告,两个报告有一点给我印象非常深:使用 ChatGPT 的用户行为中非工作消息的比例越来越大,已经占到了差不多 73%;
而使用 Claude 的用户行为中则几乎都与工作相关,AI 更多被当作工具/助手/协作者,特别是与编程以及增强人类能力这块。
两家走出了非常具有自己特色的路径:OpenAI 的发展一直延续了综合能力的提升,在推理和多模态各方面全面发展。而 Anthropic 则以代码和工具使用能力为特色,逐步形成适合真实世界软件工程任务的口碑和标签。
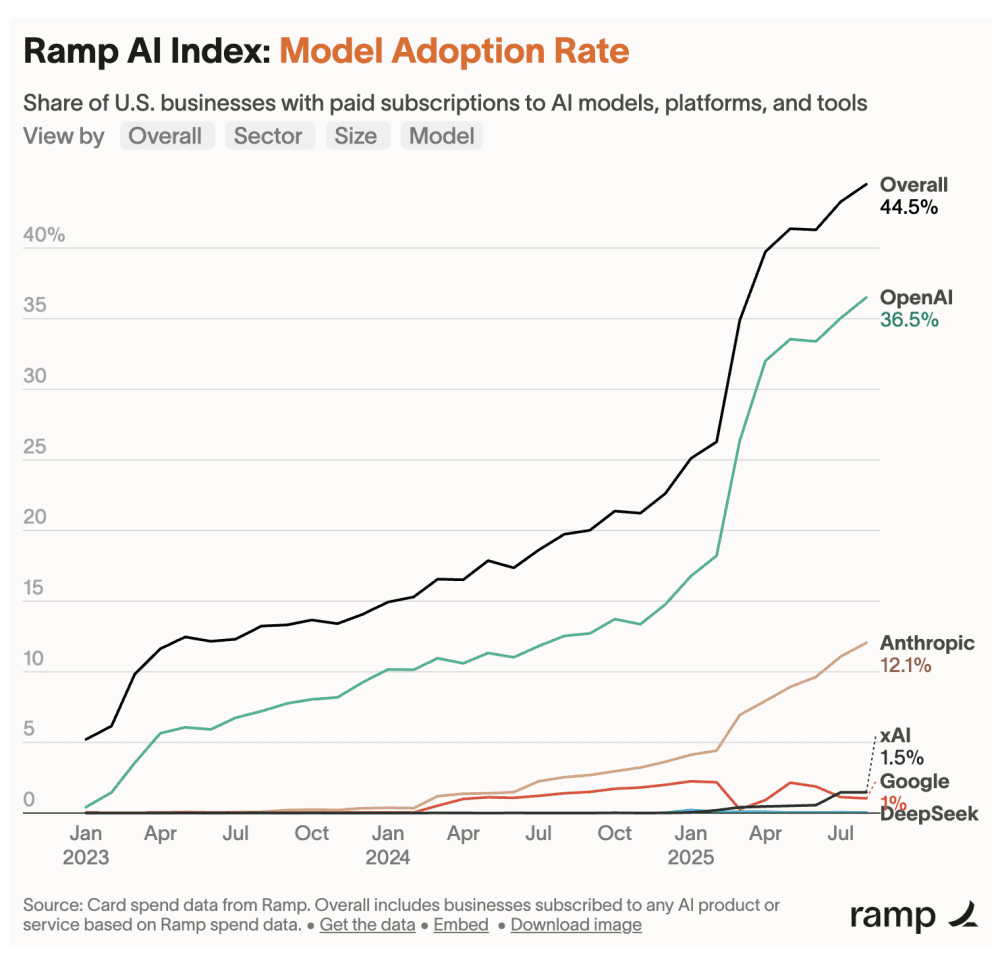
OpenAI 最新一轮融资让其估值达到了 3000 亿美金,而 Anthropic 同样达到了 1830 亿美金,可以说都挺疯狂的。
成为 Anthropic 不比追赶 OpenAI 容易
Anthropic 的发力和快速突破点是 Coding 和 Agent 能力,目前它是 Agentic Coding 这个领域的主导,自己推出的 Claude Code 也成为 Agentic Coding 里增长最快的产品,6 个月时间 ARR 达到 4 亿美金,Claude 4 上线后两月内其收入增长了 5 倍。
最近在跟一位朋友交流国内 AI 大模型未来的机会点时聊到一个反常识的观点:大家可能会觉得追赶 OpenAI 的难度要高于 Anthropic,因为前者需要同时满足天时地利人和的条件,而后者需要的是单点突破的能力。但实际上,做 Anthropic 的难度更大,因为作为追随者,大家很容易困在行业领头羊 OpenAI 设定好的技术路线图,亦步亦趋。敢于提出和验证不同的路径才有可能成为 Anthropic。
这可能就是为什么直到最近几个月,中国的AI模型公司才意识到 OpenAI 的路线不是唯一正确解,从而加快了追赶 Anthropic 的步伐。
7月初,月之暗面发布的 Kimi K2,技术博客标题就叫 Open Agentic Intelligence。并且在官方文档中首次提供了与 Claude Code 完整兼容的接入指南,可以直接在 Claude Code 中使用 K2 模型。
7月末,阿里的 Qwen3-Coder 编程模型以及智谱发布的 GLM-4.5,都在往替代 Claude Code 的方向上靠。
8月底,DeepSeek 发布的 DeepSeek-V3.1,也包括了兼容 Anthropic API 的能力,可以用与调用 Claude / Anthropic API 类似的方式调用 DeepSeek 的模型和服务。
9月初,Anthropic 严格限制来自中国企业的使用后,国内AI迅速做出了反应,希望成为 Claude 的有力替代。
Anthropic 如何成功挑战 OpenAI 设定的技术路线图?答案要从一年多之前说起。
Anthropic 的赌注
2024年3月,Anthropic 在发布 Claude 3 系列模型的时候,依然是 OpenAI 的追随者,除了强调更长的上下文,模型本身并没有什么特别突出的能力,官方强调的也是跟 OpenAI 一样的各项通用能力。
三个月后,Anthropic 模型策略的转折点开始显现。2024 年 6 月发布 Claude 3.5 Sonnet 的时候,Anthropic 第一次提出了内部的 Agentic Coding 评估基准,突出了模型在真实世界中修复代码库中的错误或添加功能的能力,重点强调“在得到指导并提供相关工具时,Sonnet 3.5 可以独立编写、编辑和执行代码,具备复杂的推理和故障排除能力。它轻松处理代码转换,使其在更新遗留应用程序和迁移代码库方面特别有效。”
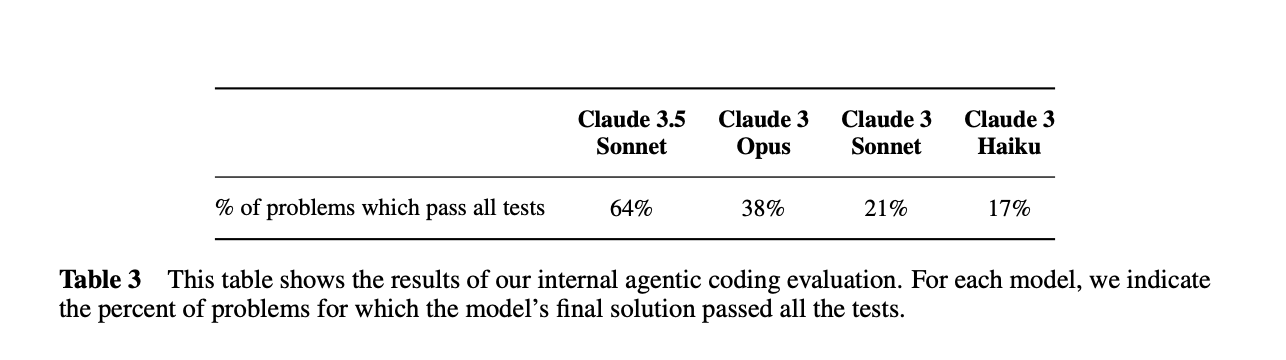
2024年10月,新版的 Claude 3.5 Sonnet(没错,这是个糟糕的产品名字,后来他们应该吸取了起名字的教训),通过 Computer use 功能,将模型“工具使用”能力提升到了一个新的阶段。这一次他们开始的全部重点都是“业界领先的软件工程能力”。OpenAI 在 8 月份发布的 swe-bench Verified 基准评测,成了 Anthropic 模型最看重的一项能力展示的窗口。这可能会让人想起 Google 发布的 Transformer 成就了 OpenAI 的 GPT 系列模型。AI 研究的开放,促进了行业的快速发展,让大家可以互相成就。
2024年11月,Anthropic 发布了模型上下文协议(Model Context Protocol),让模型的工具使用能力有机会规模化扩展。后来,这个协议几乎成为了行业里事实上的标准,Google、OpenAI 都宣布兼容,大量厂商推出了自己的MCP工具。
再后来,Claude 3.7、4.0、4.1 模型陆续发布,基于 Claude 模型的 Cursor 等编程工具成为行业热门产品,自己下场做的 Claude Code 第一次把 Agentic Coding 能力更淋漓尽致地呈现在行业面前。
至此,Anthropic 让 OpenAI 成为了 Agentic Coding 领域的追赶者,也把自己的估值推上了近 2000 亿美元的惊人水平。
避免困在 OpenAI 设定的路线图里
Anthropic 找到了突围点,但 AI 行业的其他公司被困在 OpenAI 设定的路线图里。DeepSeek R1 带来的冲击,更是让大家普遍坚信只有把 L2 的“深度思考”能力做好了,才有机会进入 L3 的 Agent 阶段。

Kimi 的创始人杨植麟最近在接受《语言即世界》的采访时,多次 cue 到了 Anthropic 和 Claude 模型,他点出 Anthropic 并没有完全按照 OpenAI 设定的 L1 到 L5 路线发展,在 L2 的推理上做得并不多,而是着重在 L3 Agent 上发力,最终取得了突破。这可能也是为什么 Kimi 的 K2 模型发力 agentic 能力,而不是优先做长思考版本的原因。
追随领头羊是一个更不需要思考的战略。如果一个中国公司的战略是紧紧跟追 OpenAI,那它几乎必然会困在 OpenAI 设定的路线图里,在 Agent 模型方面慢半拍到一拍。对于中国 AI 大模型创业公司而言,融资金额普遍有限,出牌的机会并不多,可能慢板拍就意味着掉队的开始。
这让我想起了张一鸣在某次采访中说过的一段话,“对事情的认知是最关键的,你对这件事情的理解,就是你在这件事情上的竞争力。因为理论上其他的生产要素都可以构建。”一个更直白的版本是,除了认知,其他生产要素都是可以构建的。
想要避免困在别人设定的路径里,中国 AI 行业需要更多像梁文锋和杨植麟这样的深度思考者,就像 DeepSeek 对模型 MoE 架构的探索,Kimi 对下一代深度学习优化器的探索。
月之暗面的 Kimi 模型,最早以“长文本”理念被人所知。2023 年 10 月,Kimi 刚上线时就打出了支持 20 万字输入的理念。是当时上下文最长的 AI 助手产品,大概是当时 Claude 的两倍。杨植麟甚至提出了“Lossless Long Context is Everything”的说法,这让人想到其实他的学术成名作 Transformer-XL,本质目的就是让模型从底层算法层面就能支持更长的上下文。
2025 年 1 月,跟 DeepSeek R1 同一天推出“长思考”的推理模型 K1.5 没什么声响,直到 7 月份开源了万亿参数的 Kimi K2 模型,获得技术圈的普遍认可,甚至被 Nature 发文称是中国的“又一个 DeepSeek 时刻”。在采访中,当被问到 Kimi 是否想成为 Anthropic 时,杨植麟回答说,“做中国的XXX”本身就是不成立的——“很难用这样的方式去定义。中美的语境、土壤不一样,今天更多是从全球视角去思考问题。”
对中国 AI 公司而言,Anthropic 带来的最大价值或许就是激励更多人,不仅仅做追随者,而是探索属于自己的道路。
Anthropic 可能也不是最终答案
如果站在 OpenAI 的角度,Anthropic 的成功显然是一次偷袭,他们被对手打到了一个自己不够重视的领域。他们最近的回应是 GPT-5-Codex ,一个专门针对软件开发优化的模型,以及 Codex CLI 工具。从开发者的反馈来看, GPT-5-Codex 与 Claude 模型的体验有所不同,GPT-5 更侧重于深入思考之后,再采取行动,而 Claude 更侧重于边采取行动边思考。对于很多高难度任务而言,思考清楚再动手,可能是更好的选择。
所以,Claude 也不一定就是软件工程的最终答案,对于中国的 AI 公司而言,没有野心的追随者,永远只能是追随者。
