融 5000 万美金,这个华人团队要用真实生活场景来打造持续学习 Agent 模型
持续学习自我演进已经成为 AI 行业最为关注的一个方向,Anthropic CEO Dario Amodei 在最新的一篇文章里说反馈回路已经闭合《Anthropic CEO:AI 是给人类的成人礼》,本质上也意味着 AI 正逐渐具备持续学习、甚至加速自我演进的能力。
由前 OpenAI CTO Mira Murati 创立的 Thinking Machine,也在尝试让 AI 不再依赖一次性训练,而是作为一个长期运行的系统持续成长:通过外部工具链、动态记忆网络与持续推理流,让模型在复杂任务、代码生成与跨工具协作中不断积累“经验”。
几乎在同时,国内一家叫 Mindvers(心洲科技) 的创业公司也在做类似的事情,最近完成了由美团战投领投的 A 轮融资,元禾璞华、韶音科技和老股东跟投。总融资额已近 5000 万美金,其它投资人还包括了蚂蚁、红杉、高榕和真格等。
越来越多公司开始真的把“持续学习”当成系统设计的一部分,而不是单纯的研究方向。但更关键的问题是:
AI 如果真的会持续学习,它应该发生在模型内部还是模型外部?
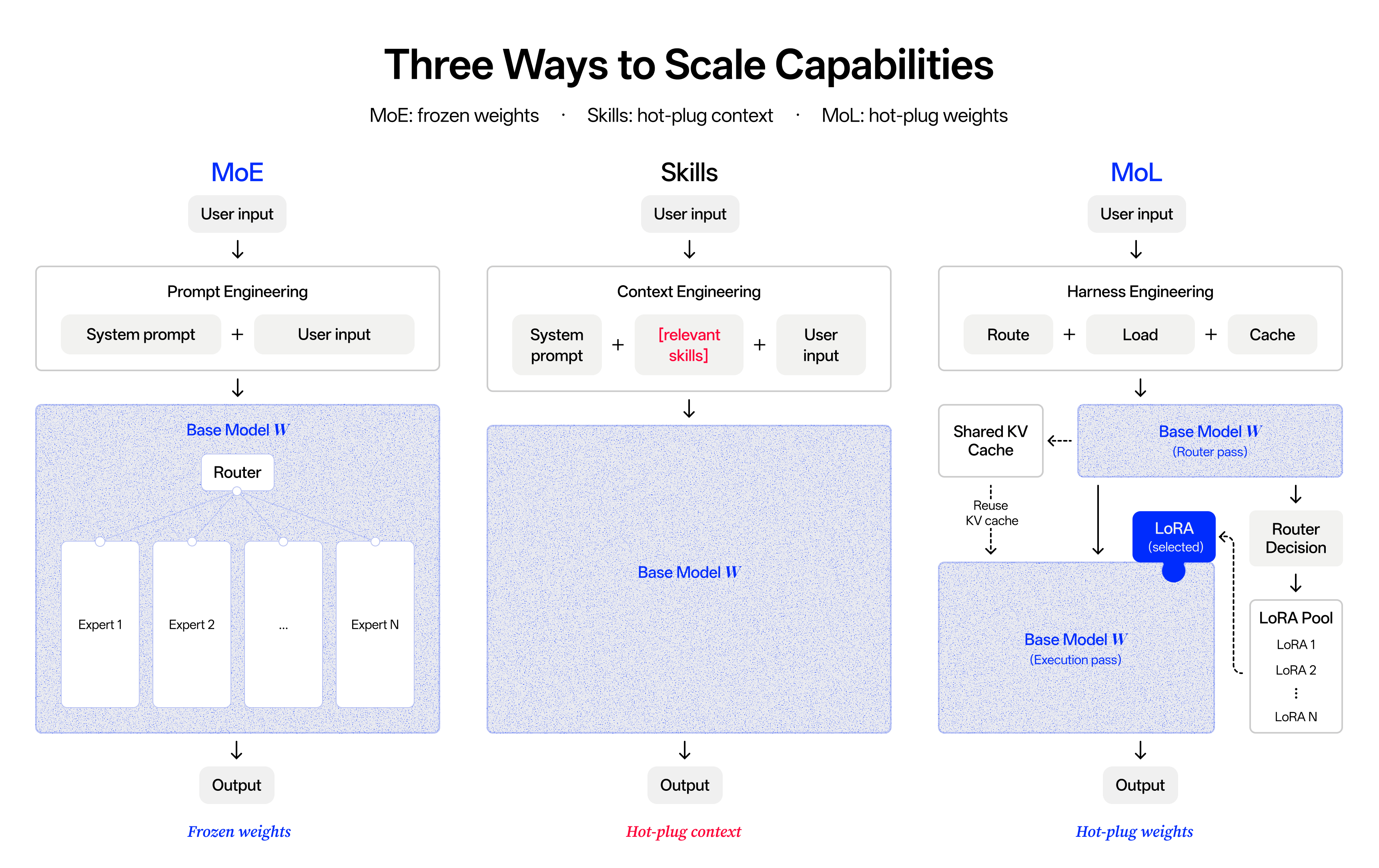
传统的路径是用 RAG、Memory、Workflow、Harness,把“学习”放在模型外部系统中实现。而 Mindverse 选择了另一条,把“学习”写到模型参数本身。
其核心判断是:
如果记忆不进入参数,就只是外挂;外挂再强,也不是能力本身。
因为在他们看来,“持续学习”不是一个系统设计问题,而是一个训练范式问题。
其核心技术路线是通过共享大脑 + 专属技能包(Mixture of LoRA),让大模型在低成本条件下获得持续扩展能力,从而更贴近真实 Agent 场景。可以将其简单拆解为:
- 共享大脑(Base Model): 大家都共享同一个聪明、庞大的通用大模型底座,提供基础的智能。
- 专属技能包(LoRA/Adapter): 在底座之上,给每个人、每个企业或每个场景挂上一个非常轻量、小巧的“技能包”(参数量只占底座的千分之五左右)。
这些“技能包”不是静态存在的,而是可以被组合、调度、替换。这个模式和最近刚拿了 Sarah Guo 领投 1500 万美金的 Trajectory 也比较类似,都属于大模型后训练 + 多 LoRA 混合 + 持续学习模式。
但 Mindverse(心洲科技)的差异在于:它从一开始就围绕真实生活场景构建整个系统。
他们首先基于真实产品中的用户行为,构建了一套生活类 Benchmark 体系,再用这一体系反向驱动模型训练,从而形成:
Agent Model + Agent Harness 协同驱动的闭环系统
在他们的定义里,一个模型是否优秀,不取决于“会不会答题”,而取决于它是否能在真实生活任务中完成完整闭环。
LivingBench:从真实产品中生长出来的评测系统
与传统静态 benchmark 不同,LivingBench 并不假设用户输入是完整的、任务是稳定不变的、环境是确定性的。相反,它刻意模拟现实生活中的不确定性,比方说餐厅突然没位置、路线因为天气变化、预算中途调整、用户临时改变目标、信息源互相冲突……
为了还原这些复杂性,LivingBench 引入了动态噪声、动态环境和动态用户反馈,使得任务本身会在执行过程中不断变化。
此时模型需要做的不只是回答问题,而是要理解用户意图是否发生变化,在信息不完整时重新规划以及处理各种突发约束。更关键的是,这套 Benchmark 本身也是持续生长的,它会从真实产品中的用户行为、失败案例、交互摩擦中不断提取新任务。
有点像是一个“从产品中长出来的评测系统”,类似的思路也出现在 CursorBench V3 中:静态题库无法衡量真实产品能力,只有动态任务才成立。
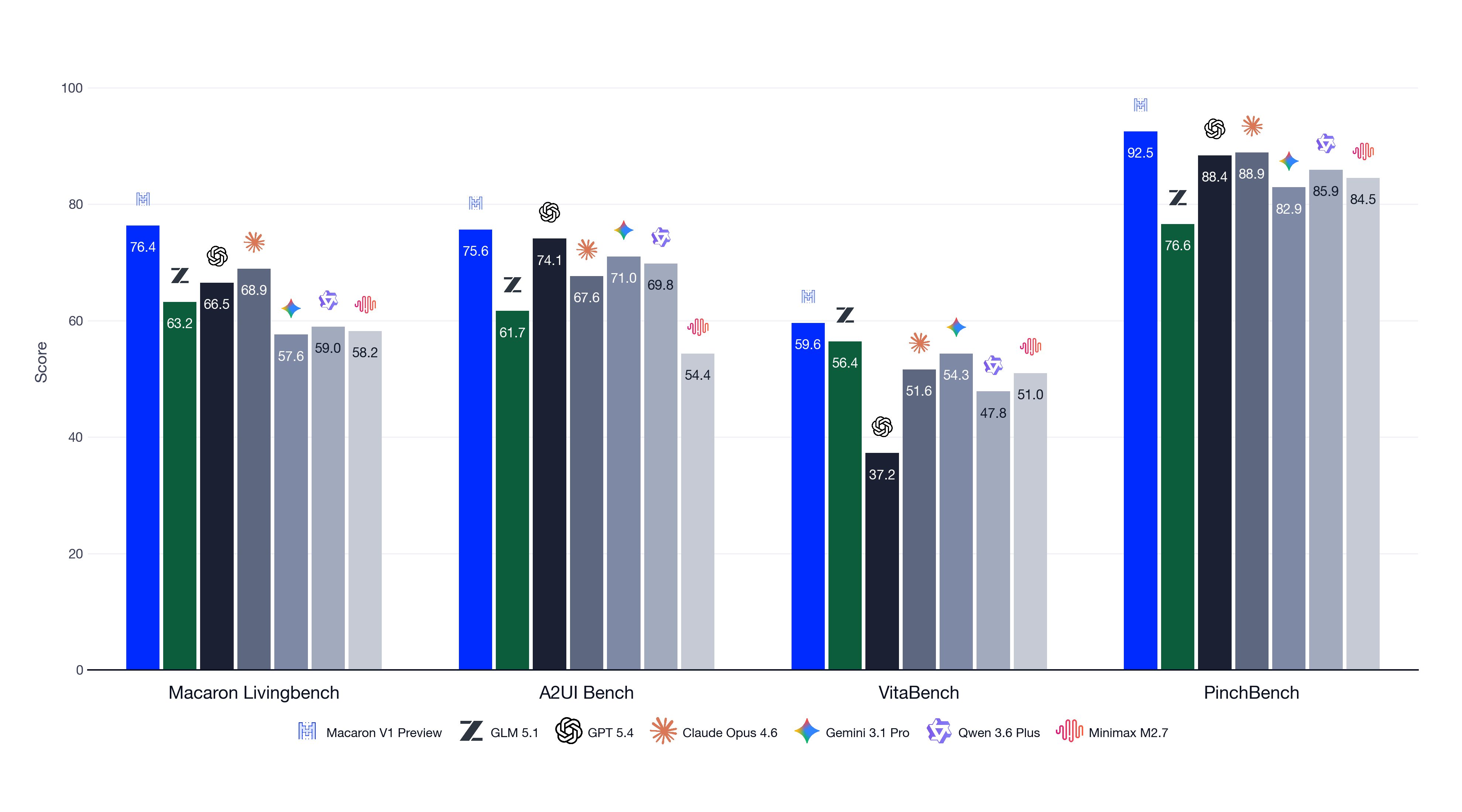
除此之外这个评测体系还包括了评估生成式 UI 能力的 A2UIBench,评测生活任务与个人助理能力的 VitaBench 以及基于 OpenClaw 的使用场景用于评估多步个人助理工作流的 PinchBench 等。
其核心逻辑是,如果模型不能在真实生活任务中稳定工作,那么在通用 Benchmark 上的领先意义有限。
Macaron-V1-Preview:生活场景优先,但不是“单点模型SOTA”
Mindverse(心洲科技)最近发布了 Macaron-V1-Preview 模型,在这套评测体系下,该公司声称它在生活类场景上表现出明显优势。
其特点不是“全面第一”,而是在生活类任务中显著领先,在通用任务中保持不掉队。它不是一个通用模型,而是一个“生活型 Agent 模型”。更擅长做的做一些具体的事情,比方说帮你预订餐厅、规划路线、管理预算等,甚至在任务进行中应对突发情况。
因此更像是一个“生活型 AI 助手 + 生成 UI + 个性化 Agent”的混合体。
Agent Model + Agent Harness:能力不只在模型里
但我觉得更重要的不是模型本身,而是上面提到 Agent Model+Agent Harness 协同的一体结构,这意味着,Agent 能力第一次不只由模型参数决定,而是由“模型 + 系统”共同决定。
在 Mindverse(心洲科技)的定义里,Macaron-V1-Preview 这个模型并不是一个孤立的模型,而是与 Agent Harness 共同构建能力边界,Agent 的能力不只在模型参数里,也在模型运行的环境里。
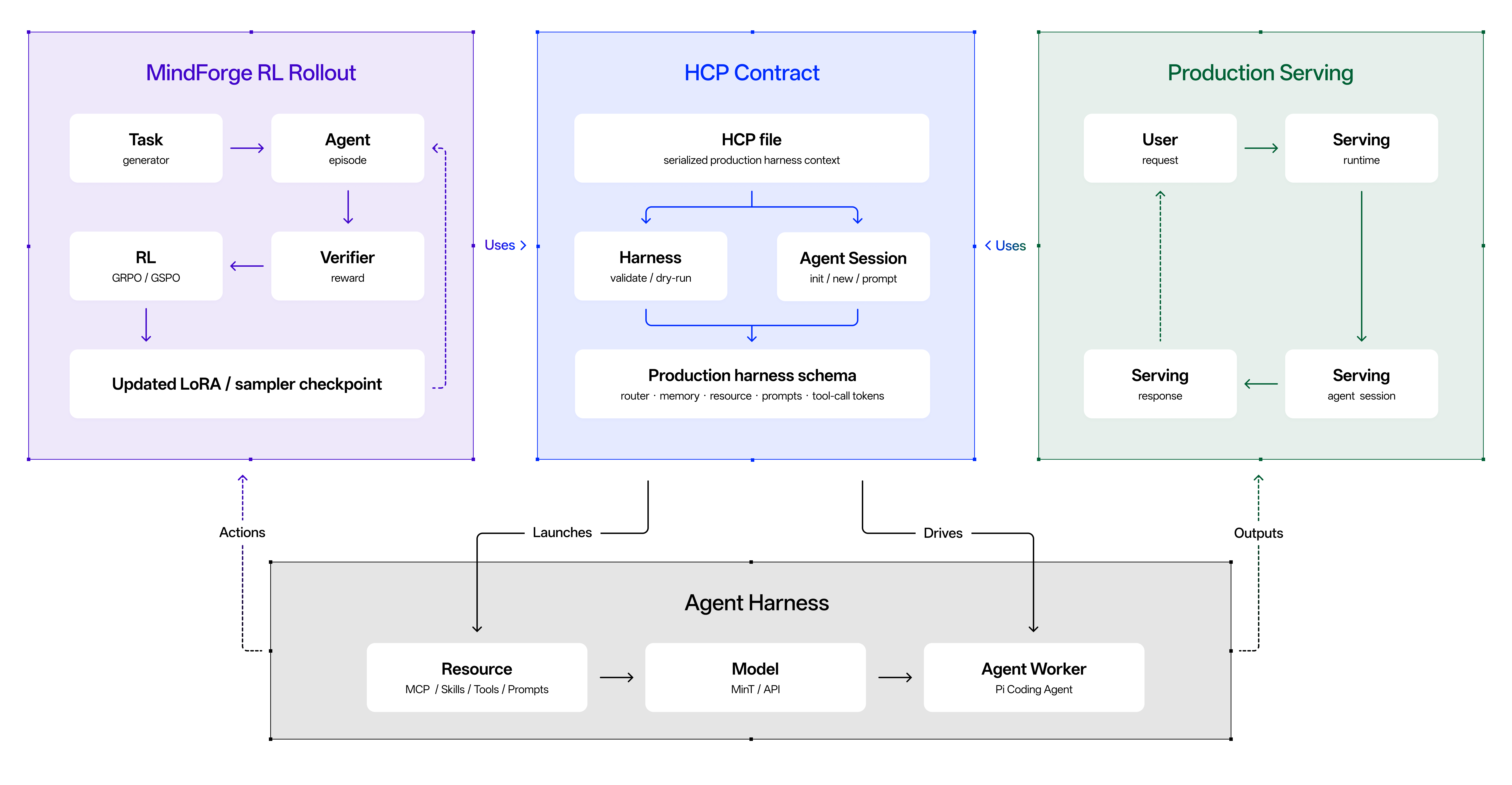
这里说的 Agent Harness,我们可以理解为模型运行时的执行系统或工作环境,就像是飞机的操纵杆和仪表盘。它包含了工具调用、多步任务轨迹管理、生成式 UI 渲染、用户反馈收集、路由机制、缓存调度以及状态管理等。
其重要的点不在于“它包含什么组件”,而在于一个结构性变化:
模型不是在一个抽象环境中训练,而是在和真实产品同一套系统中被训练、评估和部署。
这意味着训练环境和线上环境几乎是同构的。
Mindverse 早期做的 C 端产品 Macaron,就承担着 Agent Harness 的作用,官方宣称已经有 200 万用户,日活用户超过了 10 万。用户在 Macaron 中的真实行为,会反向进入训练体系,再通过后训练影响模型能力。
不过需要指出的是,其后训练并不是直接使用用户的原始数据,而是通过反馈构建模拟环境,在带噪声、带极端情况的环境中重建任务分布。这点和 Anthropic / Claude Code 的路线非常类似:
产品使用 → 反馈结构化 → 模拟环境训练 → 模型更新 → 产品能力提升
这套协同设计加上真实用户反馈,构成了一个持续改善的飞轮,使得模型能力与产品体验不断相互增强。基于这套机制,Mindverse 在训练算力不到 300 卡的情况下,实现了模型在生活场景类的领先地位。
一个仍然存在的问题:C 端数据能否支撑企业 A2UI?
不过我比较怀疑 C 端的轻量数据能否支撑未来企业级的 A2UI(生成界面),因为 C 端里常用的界面比较基础且容错率很高,而企业背后的业务逻辑极其严密的。
Mindverse 的解释是,C 端的价值不在“业务复杂度”,而在“交互模式学习”:
C 端产品核心是让我们持续获得真实交互信号,帮助我们把 A2UI 的底层交互能力训练出来;在进入企业场景时,再通过企业私有数据、合成数据、业务规则和安全架构完成领域适配。
日常前端生成更多考验的是一次性生成一个静态页面,本质上更接近代码生成能力。A2UI 的核心挑战更偏向实时交互:在用户当前意图下,快速生成一个能降低认知负担、并且可以被用户直接操作的界面。
从这个角度看,C 端数据的价值,主要体现在训练模型理解“什么样的信息应该被结构化”“什么样的交互能降低用户负担”“用户在什么时刻需要按钮、表单、确认卡片或结果视图”。这些是跨场景的交互能力,不完全依赖某一个行业的数据。
企业场景则需要结合企业自身的业务规则、权限体系、审批流程和内部数据进行适配。在训练 A2UI 时,不只依赖真实用户反馈,也会使用大量合成数据、User Simulator 和自动化评测环境,让模型在更复杂、更高覆盖度的场景里学习。
从这个角度看,Mindverse(心洲科技)的核心不只是一个模型,而是一套完整路径:
从真实产品出发定义问题,再用问题反推 Benchmark,最后反推模型训练方式。
如果这一路径成立,那么 AI 行业的竞争重点可能正在发生变化:从“谁模型更大”变成“谁更接近真实任务系统”,模型不再是中心,系统(训练 + 产品 + 数据闭环)可能才是中心。
作为中国第一家 Neo Lab,Mind Lab 的阵容不可小视。公司创始人 Andrew 在深圳清华大学研究院任研发中心主任,实验室负责人马骁腾是清华自动化系博士、博士后,核心研究团队约 30 人,团队成员累计发表 200 篇顶会论文,总引用超过 5 万次。
其中,基础设施负责人来自 DeepSeek,算法负责人来自字节 Seed,模型团队成员来自清华、MIT、NVIDIA、xAI 等机构,长期专注于模型训练、强化学习和高性能推理架构领域。
