
这是一篇只对付费会员开放的文章,请先订阅成为会员
由于海外的创业者很多都是面向 B 端企业级,因此他们对 B 端市场具有更深刻的洞察。去年的时候,Box 创始人 Aaron Levie 分享过一个我非常认同的观点,他认为 AI 最大的价值点,是对非结构化数据的处理《Box 创始人:我疯狂看好 AI 的原因在于非结构化数据的处理》。
特别是在企业内部,非结构化数据可能占据了 90% 的信息,在之前要么不能处理要么处理效率非常低,而 AI 正在彻底改变这种状态。
Aaron Levied 说,自从创办 Box 以来,我们从未见过像今天这样在处理企业信息方法发生更大的转变。之前,在企业中使用我们的结构化数据相对简单,我们可以查询、计算、合成、总结和分析任何可以在数据库中构建的东西,也就是我们的 ERP、CRM 和 HR 系统中的数据。
但实际上,这只是公司信息的一小部分,企业里结构化数据只占到了 10% 左右,而非结构化数据占据了 90%,比方说文档、合同、产品规格、财务记录、营销资产和视频等。
之前,这些信息往往没有得到很好的利用,虽然可以存储、发送、共享和搜索它,但无法深入理解这些信息中的内容。
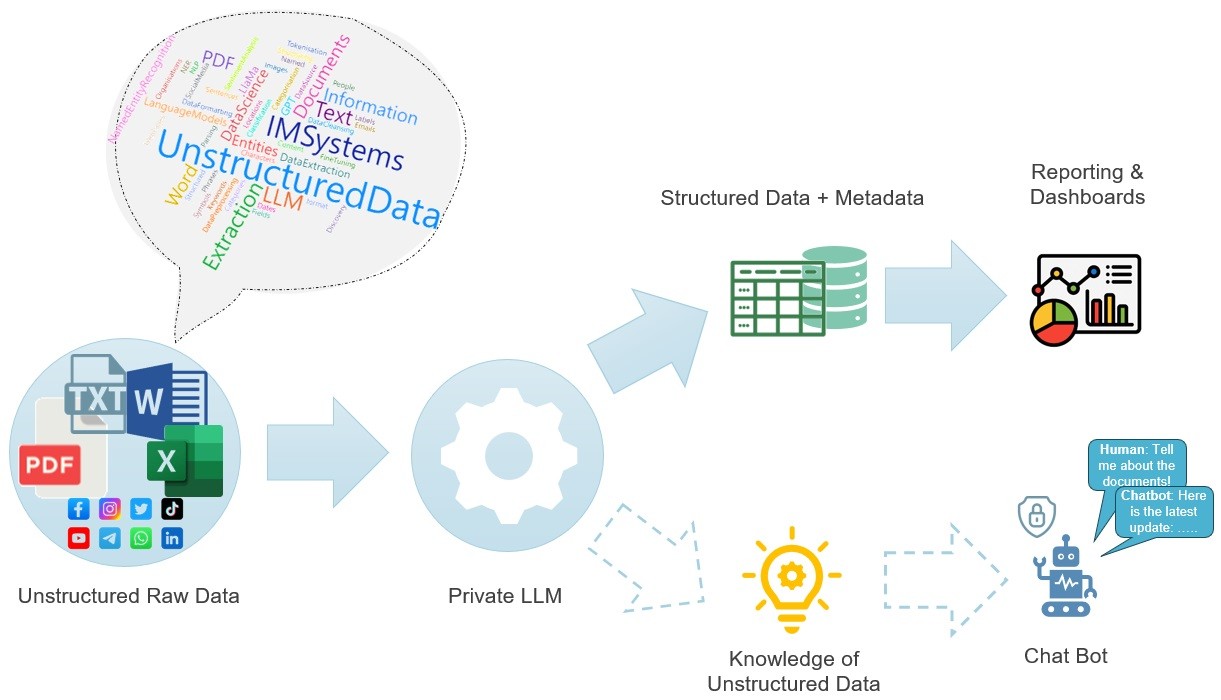
而生成式 AI 是有史以来第一次让我们可以与非结构化数据进行对话,多模态模型特别允许我们使用计算机处理这些内容,而且是以无限的规模和速度执行人类可以执行的任何任务。
因此,当我们在企业中处理这些信息时,就完全改变了游戏规则。瞬间,我们的内容就从偶尔被触摸的数字工件变成了企业中任何人都可以随时利用的数字内存。
突然之间,你拥有的信息越多,不再是信息更难找到和理解,而是相反。我们进入了一个世界,你的数字信息将成为你最宝贵的资源之一。
当你能够了解内容(如合同、发票或数字资产)的内部内容并提取其结构化数据时,你几乎可以自动化任何工作流程。
之前 Slow Venture 的合伙人 Sam Lessin 也发表过类似的观点,认为类似 NotebookLM 这种产品出来后,所有结构化的 CRM 公司都没有未来《NotebookLM 是新的 CRM,所有结构化 CRM 都没有未来》。

AI 笔记(会议)类转录产品本质上我觉得也是对非结构化数据(语音)的处理,正如 Otter 的创始人所说,会议是知识工作者最大的实践黑洞,而语音是尚未被充分利用的数据金矿,《Otter 成首个超 1 亿美金 ARR 的 AI 笔记,10 人团队做了个 1000 万美金 ARR 的 AI 健身》。
后续 Otter 的延伸路径也差不多如 Levied 所说,打通更多维度数据,通过 Agent 提供更多企业级自动化解决方案。
Glean 的快速增长我觉得也体现了这一趋势,只不过它更加强调与公司内部环境的结合《Glean ARR 突破 2 亿美金,一个超简单的 AI 绘本产品一年卖了 600 万美金》,企业的 CEO 和高管们都在寻找一个安全、可靠、更适合员工的 ChatGPT 版本。而 Glean 做的事情差不多就是将 ChatGPT 为消费者带来的能力带给企业用户,并融入他们的公司环境:
客户在使用人工智能时面临的最大挑战是,人工智能技术实际上并非为他们的公司打造,大多数人工智能技术都是基于互联网上的公共数据。所以当你把那些模型带到你公司内部,并且试图让他们在内部工作时,最大的问题是他们其实并不了解你们的业务运作方式和背景。
之前 a16z 投了一个面向金融领域处理非结构化的 AI 搜索产品,而最近一个做通用化,只针对将非结构化数据结构化这个需求做的 Infra 产品,可能更能代表这个趋势,它先是在半年左右从 0 做到了超百万美金的 ARR,之后半年多时间 ARR 继续呈 10 倍级增长超过了 1000 万美金,有传言甚至称其 ARR 可能已经
订阅 Memo 邮件列表,过滤噪音,捕捉最具价值的创投行业信号
最顶尖的 AI 行业创业者和投资人都在看
